主题 解释结果 会话命令 另请参见
这些数据是学期开始时对某个 MBA 班进行的调查的结果。数据中包含部分关于学生的教育和经济情况的特征数据,并用它们来检验学生有哪些信用卡。
1 打开工作表“MBA调查.MTW”。
2 选择统计 > 回归 > 二进制 Logistic 回归 > 拟合二进制 Logistic 模型。
3 在响应中,输入 AmEx。在连续预测变量中,输入现金 年收入。在类别预测变量下,输入最高学历。
4 单击模型。在预测变量中,突出显示现金。在按阶数排列项的旁边,单击添加。
5 在预测变量中,突出显示现金和年收入。在按阶数排列交互作用的旁边单击添加。在每个对话框中单击确定。
6 选择 统计 > 回归 > 二进制 Logistic 回归 > 拟合二进制 Logistic 模型。
7 在响应中,输入 MC。在连续预测变量中,输入 GMAT 现金 年收入。在类别预测变量下,输入性别 最高学历。
8 单击模型。
9 单击默认值。
10 在每个对话框中单击确定。
11 选择统计 > 回归 > 二进制 Logistic 回归 > 响应优化器。
9 在目标下,AmEx 和 MC 均选择望大。
10 单击设置。
11 在下限中,MC 输入 0.9,AMEX 输入 0.8 。
12 在每个对话框中单击确定。
会话窗口输出
二值 Logistic 回归: AmEx 与 现金, 年收入, 最高学历
二值 Logistic 回归: MC 与 GMAT, 现金, 年收入, 性别, 最高学历
响应优化: MC, AmEx
参数
响应 目标 下限 目标 上限 权重 重要度 MC 最大值 0.9 1 1 1 AmEx 最大值 0.8 1 1 1
解
MC AmEx 解 GMAT 现金 年收入 性别 最高学历 拟合概率 拟合概率 复合合意性 1 44 349 114424 男性 研究生 1.00000 1.00000 0.99999
多响应预测
变量 设置 GMAT 44 现金 349 年收入 114424 性别 男性 最高学历 研究生
拟合值 响应 拟合概率 标准误 95% 置信区间 MC 1.00000 0.00001 (0.06415, 1.00000) AmEx 1.00000 0.00000 (0.00053, 1.00000) |
图形窗口输出
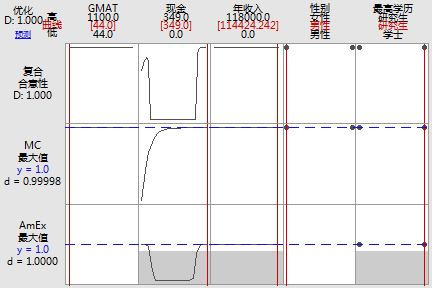
这两个响应的合并或复合合意性约为 1。
要得到此合意性,需将因子水平设置为“解”下显示的值。也就是说,该学生的经企管理研究生入学考试 (GMAT) 分数为 44,该学生携带 349 美元现金,该学生的年收入为 114,424 美元,该学生为男性,并且该学生拥有硕士学位。置信区间表示这些预测的精度,该区间非常宽。尽管预测显示的概率较高,但此模型提供的置信度并不高。
在此情况下,GMAT 分数的高、低值可引起对数据问题的注意。报告分数 1100 的学生提供的是研究生入学考试分数而不是其 GMAT 分数,而报告分数 44 的学生仅提供部分考试的结果。调查员更正数据后,他们重新拟合了模型。
如果要调整此初始解的因子设置,则可以使用该图。移动垂直条形以更改因子设置,并观察响应的单个合意性 (d) 以及复合合意性如何变化。
请记住,这些结果都以模型方程为基础。在解释图之前,应确保模型是合适的。