主题 解释结果 会话命令 另请参见
您是一位葡萄酒制造商,希望了解酒中的化学成分与感官评价之间的关系。您有 37 个 Pinot Noir 酒样本,每个样本都由 17 种元素浓度 (Cd、Mo、Mn、Ni、Cu、Al、Ba、Cr、Sr、Pb、B、Mg、Si、Na、Ca、P、K) 和一组评审员根据酒的芳香度给出的分值描述。您希望根据 17 种元素预测芳香度分值,并确定 PLS 是适当的技术,因为样本对预测变量的比率较低。数据引用自 [12]。您希望在此模型中包含所有元素 (Cd-K) 和所有包含 Cd 的双向交互作用。
1 打开工作表“葡萄酒芳香度.MTW”。
2 选择统计 > 回归 > 偏最小二乘。
3 在响应中,输入芳香度。
4 在模型中,输入 Cd-K Cd*Mo Cd*Mn Cd*Ni Cd*Cu Cd*Al Cd*Ba Cd*Cr Cd*Sr Cd*Pb Cd*B Cd*Mg Cd*Si Cd*Na Cd*Ca Cd*P Cd*K。
5 单击选项。
6 在交叉验证中,选择逐一剔除法。单击确定。
7 单击图形,然后选中模型选择图、响应图、标准系数图、距离图、残差与杠杆率和载荷图。取消选中系数图。
8 在每个对话框中单击确定。
会话窗口输出
PLS 回归:芳香度 与 Cd, Mo, Mn, Ni, Cu, Al, Ba, Cr, Sr, Pb, B, 毫克, Si, Na, Ca, P, K
方法
交叉验证 逐一剔除法 要估算的分量 集合 已估算的分量数 10 已选定的分量数 4
芳香度 的方差分析
来源 自由度 SS MS F P 回归 4 34.5514 8.63784 41.55 0.000 残差误差 32 6.6519 0.20787 合计 36 41.2032
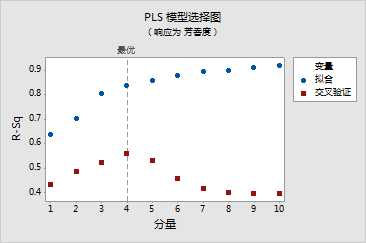
芳香度 的模型选择和验证
分量 X 方差 误差 R-Sq PRESS R-Sq(预测) 1 0.158849 14.9389 0.637435 23.3439 0.433444 2 0.442267 12.2966 0.701564 21.0936 0.488060 3 0.522977 7.9761 0.806420 19.6136 0.523978 4 0.594546 6.6519 0.838559 18.1683 0.559056 5 5.8530 0.857948 19.2675 0.532379 6 5.0123 0.878352 22.3739 0.456988 7 4.3109 0.895374 24.0041 0.417421 8 4.0866 0.900818 24.7736 0.398747 9 3.5886 0.912904 24.9090 0.395460 10 3.2750 0.920516 24.8293 0.397395 |
图形窗口输出
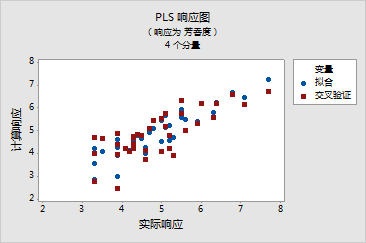
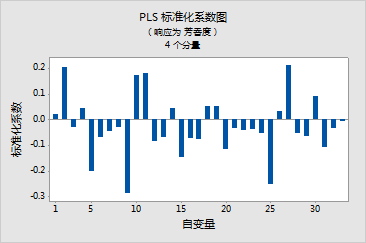
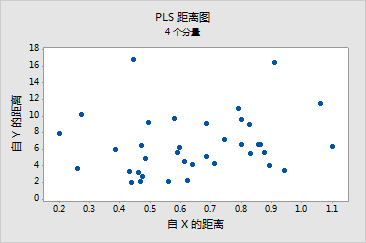
- 观测值 14 和 32 在 Y 轴上的距离值较大
- 第 1 行和第 37 行中的观测值在 X 轴上的距离值较大
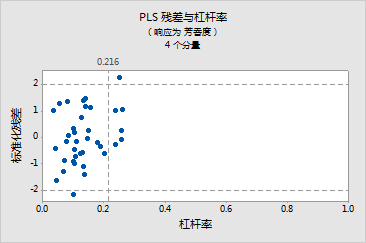
残差与杠杆率图表明:
- 由于观测值 3 在水平参考线之外,因此,观测值 3 是一个异常值
- 观测值 5、12、14、23 和 37 具有杠杆率极值,因为它们位于垂直参考线的右侧