Minitab提供了全面而强大的回归分析 工具,从简单的线性关系到复杂的多变量非线性模型,能够满足不同行业和应用场景的需求。 一、回归分析基本概念 回归分析是研究变量之间相关关系的统计方法,主要用于预测和因果关系分析。在Minitab中,回归分析可以帮助您:
- 建立预测模型,根据自变量(X)预测因变量(Y)
- 确定影响结果的关键因素
- 优化工艺参数和业务流程
- 验证测量系统的准确性和线性
二、Minitab回归分析类型全览 1. 根据响应变量类型分类 线性回归模型
- 适用场景:响应变量(Y)是连续型数据
- 主要类型:
- 简单线性回归:1个X变量 → 1个Y变量
- 多元线性回归:多个X变量 → 1个Y变量
- 非线性回归:变量间存在曲线关系
Logistic回归模型
- 适用场景:响应变量(Y)是类别型数据
- 主要类型:
- 二元Logistic回归:Y只有两个类别(是/否,合格/不合格)
- 名义Logistic回归:Y有多个无序类别(产品类型A/B/C)
- 顺序Logistic回归:Y有多个有序类别(差/中/优)
Poisson回归模型
- 适用场景:响应变量(Y)是计数型数据(缺陷数、事件发生次数)
2. 特殊回归方法
- 适用场景:X和Y变量均存在测量误差
- 典型应用:仪器校准、方法比对
偏最小二乘回归
- 适用场景:预测变量数量多且存在多重共线性
- 典型应用:化学光谱分析、生物信息学
稳定性研究
- 适用场景:产品保质期分析和预测
- 典型应用:制药、食品行业
表格化:
| 类别 | | | | | | | 建立连续响应变量与预测变量间的线性关系,用于预测、优化和确定关键因素。 | | | • 多元线性回归: 2个或多个X(可包含类别预测变量) | | | 建立连续响应变量与预测变量间的已知非线性关系(曲线关系)。 | 需要指定具体的非线性模型函数(如指数、S型、自定义方程)。适用于物理、化学、生物等领域已知其内在曲线规律的过程。 | | | | | • 二元Logistic回归: Y只有两个结果(是/否,通过/失败)。 | | • 顺序Logistic回归: Y有多个自然顺序的类别(如:差、中、优;1=非常不满意,..., 5=非常满意)。 | | • 名义Logistic回归: Y有多个无序的类别(如:产品类型A、B、C;颜色红、蓝、黄)。 | | | | 预测计数型响应变量(如缺陷数、事件发生次数)的发生率。 | | | | | 模型诊断与验证,判断模型是否满足统计假设(线性、正态、等方差、独立),这是结果可靠的前提。 | 标准输出为“四合一”残差图:正态概率图、残差与拟合值图、残差 直方图、残差与顺序图。 | | | | 当预测变量(X)和响应变量(Y)均存在测量误差时,建立两者的线性关系。 | 最小化点到直线的垂直距离(而普通回归只最小化Y方向的误差)。主要用于仪器校准和方法比对。 | | | 处理预测变量(X)数量极多且存在严重多重共线性的数据。 | 通过提取潜变量来降维,既能进行回归预测,也能很好地解释变量间的结构。特别适用于化学光谱、生物信息等“宽数据”领域。 | | | | 基于回归分析预测产品的保质期,评估产品特性(如药品含量)随时间降解的趋势。 | 本质是带有批效应分析的线性或非线性回归。是制药、食品等行业必须进行的分析。 | |
三、回归方法选择决策流程 以下流程图展示了如何根据数据类型和分析目的选择合适的回归方法:
如何根据数据类型和分析目的选择合适的回归方法

四、最佳实践建议
- 数据准备:确保数据质量,处理缺失值和异常值
- 变量选择:基于业务知识选择有意义的预测变量
- 模型简洁:遵循"简约原则",避免过度拟合
- 结果验证:使用新数据验证模型预测能力
- 业务解释:统计显著性需与业务意义结合
核心要点:始终从业务问题出发,明确分析目标,选择合适的回归方法,并进行严格的模型诊断,确保结果的可靠性和实用性。
| 

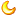

 发表于 2025-10-10 17:24:09
发表于 2025-10-10 17:24:09

 发表于 2025-10-10 18:49:04
发表于 2025-10-10 18:49:04

 发表于 2025-10-11 08:14:15
发表于 2025-10-11 08:14:15

