|
|
本帖最后由 willdemon 于 2022-5-15 16:39 编辑
大家好,今天开个贴,谈一下统计过程控制图。此贴会长期更新,我们先从一些基础慢慢聊起, 然后一起探索一些新的东西。以下表格,用于追踪更新进度。
| 章节 | 更新日期 | 内容介绍 | | 一 | 2022/5/6 | 休哈特的贡献、统计过程控制的基本理念、控制图的运用流程 | | 二 | 2022/5/8 | 常见控制图有哪些类型? 选R图还是S图?什么是合理子组?子组样本数量多少为宜? | | 三 | 2022/5/12 | 抽样频率多少为宜?ARL的缺陷。ATS与抽样成本考量。 | | 四 | 2022/5/13 | Xbar-R数据整理,数据检验,制图及判异。 | | 五 | 2022/5/15 | CUSUM控制图的制作说明 |
章节一

关于统计过程控制图相关的资料已经很多了,大家可以参考六西格玛红蓝宝书的相关内容。所以本贴的主要内容并非详细介绍常见控制图的制作和判异规则,而是围绕SPC control chart的基本概念应用,一些常见资料中涉及较少的知识点,此外一些新的想法和应用,就本人所了解的内容,跟大家做一些沟通交流,相互学习,共同进步吧。
首先讲一讲统计过程控制的来源,当然只是本人的一家之言:
说到SPC统计过程控制及控制图,必然谈到其发明人 - 休哈特。关于休哈特本人及其提出控制图的历史内容,相信包括本站在内的网络上有大量的相关资料。这里就不再展开,只说两点:
1、关于休哈特的贡献: 不单是控制图,实际上他先于戴明提出了一种闭环式的工作开展模式,为PDCA这一经典业务模型的出现奠定了基础,参考下图(以前做的资料):
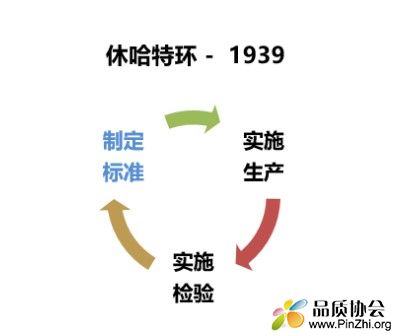
2. 休哈特控制图,以及道奇的抽样检验的出现,使得质量从单纯的检验,发展到统计质量控制阶段。这一技术需求促使质量管理这一行业的诞生。可以讲,休哈特不仅将质量管理提升到质量2.0时代,同时称得上是质量管理这一职业的“祖师爷”了。
下图是以前做的培训资料:
下面聊聊统计过程控制的基本理念:
还是以一张图来说明:
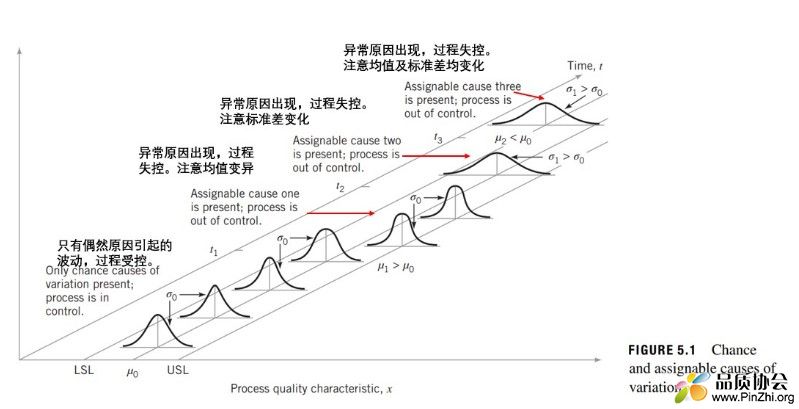
1. 过程中单一产品的质量特性可以测量并使用数值表现。
2. 这一特性数值的整体分布符合或近似符合正态分布,这是因为此特性受多种因子的累加影响。(注意,正态分布并非意味着正常态,自然界中高度独立的因子通常不符合正态分布)
3. 正态分布可使用其统计量:总体均值和总体标准差来进行描述。总体不可知时,可使用样本均值和样本标准差进行估计。
4. 如影响特性分布的因子稳定时,则符合正态分布的整体数据应集中在均值±3σ范围内。可通过调节因子使整体分布满足质量要求范围,此时设置±3σ为控制范围,如数据仅在此范围内波动,则判断过程受控。
5. 如影响特性分布的因子产生变异时,则整体分布发生变化,质量特性数据便会出现偏离控制范围的趋势或直接超出控制范围,说明影响整体的因子发生变化,过程失控。
6.通过抽样数据的分布判断整体是否已发生变化图示方法即统计过程控制图。
控制图运用的一般步骤:
因为控制图的制作基于过程受控的前提,其基本步骤如下:
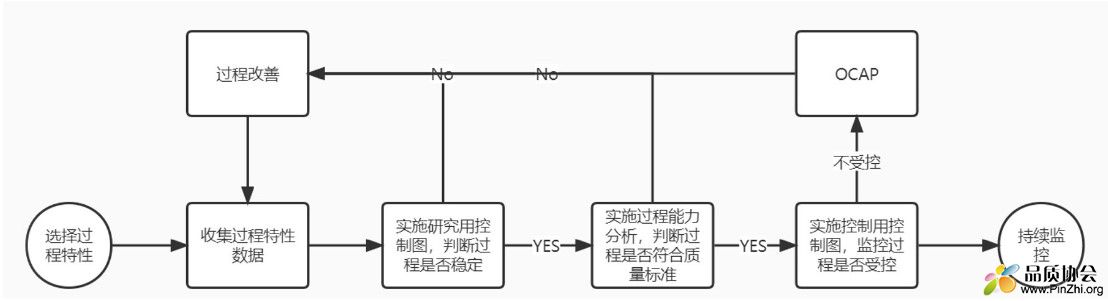
控制图仅是一种统计过程监控工具,若想达成质量改进,必须配合以闭环的质量改进活动。
今天先简单聊到这里,下次我们聊聊常见的控制图有哪些,并使用Minitab进行简单示例。
章节二

大家好,今天我们继续聊控制图。
本贴不在于具体讲解控制图的制作和判异,所讲内容更多是聚焦于点,跳跃式,内容松散随意。因此如能对常用控制图的使用有一定的了解,比如读读六西格玛红蓝宝书,将有助于判断和思考本贴的内容。
常见单变量SPC控制图的种类:
常见控制图的种类依照数据类型(离散数据与连续数据)分为计数型控制图和计量型控制图。
计数型控制图主要包含不合格品数,不合格频率,缺陷数,单位缺陷数控制图等。
计量型控制图可以针对各种连续数据使用。
如下常用单变量控制图的运用情景(发懒了,直接Copy别人家的培训资料),注意下图欠缺了计数型数据需使用控制图诊断,如存在过/欠离散情况时,应考虑使用Laney P'/U' 控制图。(顺便说下,这个'在英语里念prime)
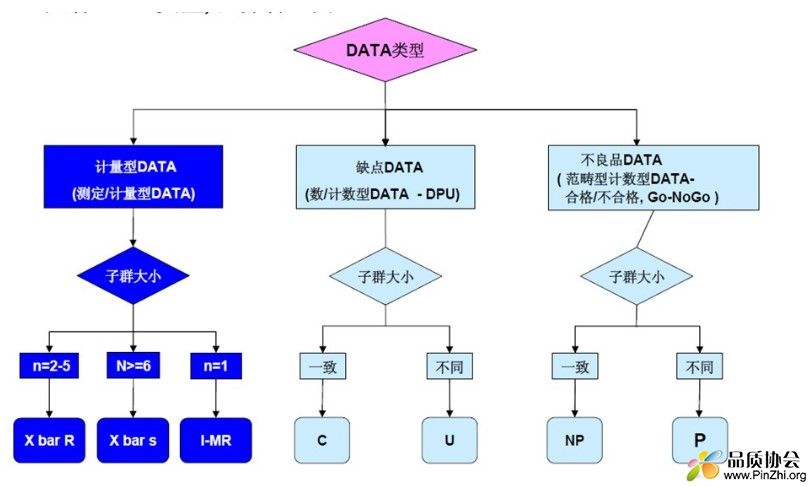
关于以上各控制图的数据要求,判异规则等,大家可以参考AIAG的SPC最新版手册,上面有详细讲解,这里就不展开了。
下面进入今天的正题,我们讲几个知识点。
选择R图还是S图?
无论是R图还是S图,其目的都是为监控过程离散程度的变异,那么为什么会有R和S两种控制图,是为了不同的样本量进行开发的吗?
R图是早于S图存在的,究其原因主要是,在计算器和计算机尚未普及的时代,计算标准差实在是太费时耗力了...
统计学家经过观察研究,捋清了极差与标准差的商,即相对全距w的分布。w = R/σ, w的数学期望值E(w) = d2 ,其取值依赖于样本数量。以上公式经过转化 d2(n)= R/σ --> R = d2(n)*σ --> σ = R/d2(n), 成为一种使用R估计总体标准差的方法。由于R非常易于计算,d2可以直接参照常量表,因此使用R来估算总体标准差的R控制图便应运而生。
随着计算机时代的到来,样本标准差s的计算已经非常简单,使用计算机计算样本标准差,再使用纠偏常量c4, 可以轻松估算总体标准差σ = s/c4(n), 因此S控制图的应用才逐渐推广开来。
那么到底使用R图还是S图呢,因为R = Max -Min, 只反映了最大值和最小值之间的差异,而s反映了每个样本与均值的差异。因此R其实存在信息缺失的缺点,特别是当样本量较大时:以下对比了R与S在不同样本量下统计有效性的差异,可见n=10时,R的统计有效性只有s的85%。(下图摘自 Introduction to Statistical quality control, 8th edition, Montgomery)
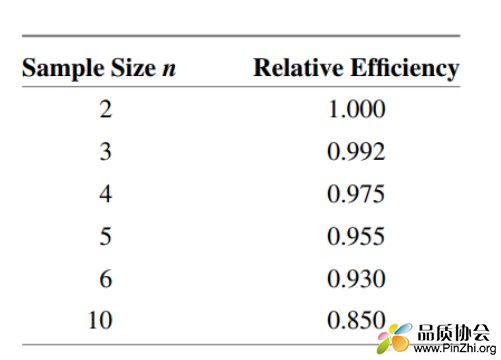
因此,当单个子组样本量n较大时,必须要使用s控制图。n的具体标准,不同的手册、书籍给出标准的不尽相同,使用者应参考所在行业的通用标准或权威的标准。
什么是合理子组:
让我们先看看六西格玛红宝书是怎么讲的: 组内波动仅由偶然原因引起,组间波动主要由异常原因引起。
这个好像比较理论化。简单来讲,休哈特认为即便属于同一主体的数据,其在时间维度上依然存在波动性。
下图显示抽样均值随时间维度而波动。
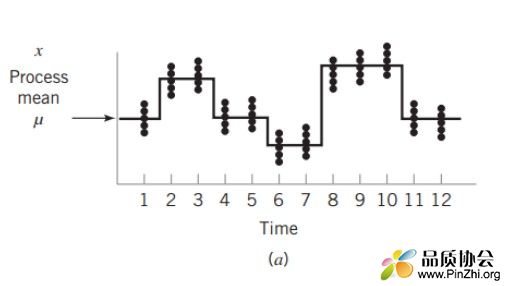
让我们借用可控因子和噪声因子的概念。假设某工序固定设备机台号、材料厂商和工艺条件进行SPC管控,此时机台,材料厂商和工艺条件就是可控因子,在可控因子已经固定不变的情况下,按时抽样的数据均值和标准差仍然存在波动,其波动来源可能来自设备的异常、材料批次的差异,作业环境的变化等噪声因子的波动,而这些因子的波动一般都体现在时间维度上。
那么,下面就是我个人理解的合理子组概念: 在可控因子固定情况下,噪声因子波动最小化的抽样组就是合理子组,而合理子组就是通过短时间连续取样来达成的。
子组样本数量多少为佳?
这个问题我曾经也不是很清晰,以为子组数量主要看检验成本和测试时间(一般以批次首件或抽检数据做SPC,力求对生产流动影响最小化)。
实际上子组数量与检验的β风险(纳伪风险,可以理解为漏报率)直接相关。(关于检验的风险,可以参考我的另一篇帖《检验合集》)
让我们以统计检验的角度来认识控制图,实际上控制图就是以给定的α风险(即上下控制线),检验抽样数据较理论总体统计量(即控制中线)是否存在统计意义上显著的偏离。
休哈特设计控制图时,为了保证α风险(可以理解为严判率)尽量低,设定控制线为相应常量系数乘以三倍标准差。按照整体符合正态分布的前提,此时的显著水平1-a = 99.7%(正态分布3σ内的概率),即α=0.3%。
在α风险给定和总体标准差已知的情况下,参照如下公式,β风险主要由样本数量和检验差异δ确定:
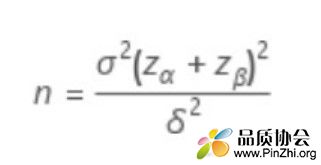
以上公式转换为 nδ² = σ²(Zα + Zβ)²,其中σ和Zα已给定,可以作为常数。当给定δ情况下,n越大,则Zβ越大,等同于β越小。因此,可以认为子组样本越多,则检验的β风险越小。
以下以单样本均值的检验为例:假设受控总体符合均值为0,标准差为1的正态分布。此时为检验出后续生产样本均值的变异是否超过总体均值>1.5σ,需要多少样本才能保证检验功效(即1-β,即准确识别变异的概率)在90%以上。
使用Minitab的功效和样本数量 ->单样本Z,参考下图设置。 可以看到,若样本量为n = 5,则检验功效不足70%,即有30%的几率漏判异常。而当样本量n=8时,检验功效基本达到90%。如果设定检验差异为> 1σ,则此时即便n=10,检验功效也仅有60%。
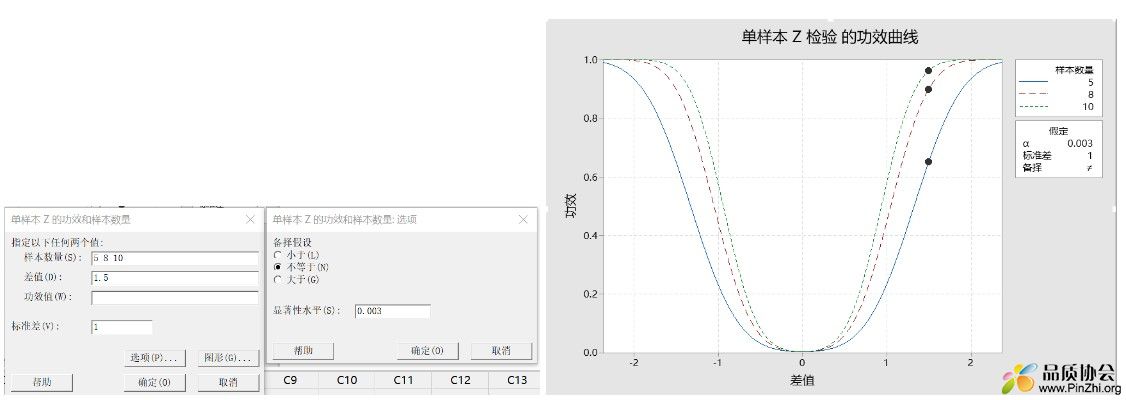
在此总结,子组样本数量越多,检验功效越大,越能识别更小的变异。
那么,如果考虑抽样的成本和对生产效率的影响,不能提高子组样本量的时候,是否意味着只能接受较高的漏报率?
其实聪明的朋友能看出,上面的检验功效计算公式已经给出答案:
nδ² = σ²(Zα + Zβ)², 在n,δ,σ给定的情况下,想要提高Zβ,只能降低Zα。也就是在接受严判率上升的情况下,将控制线加严至2或2.5个σ。以下以2σ为例,此时α = 4.6%。
仍以上题为例,可以看到当n=5时,检验功效已经达到90%以上了。
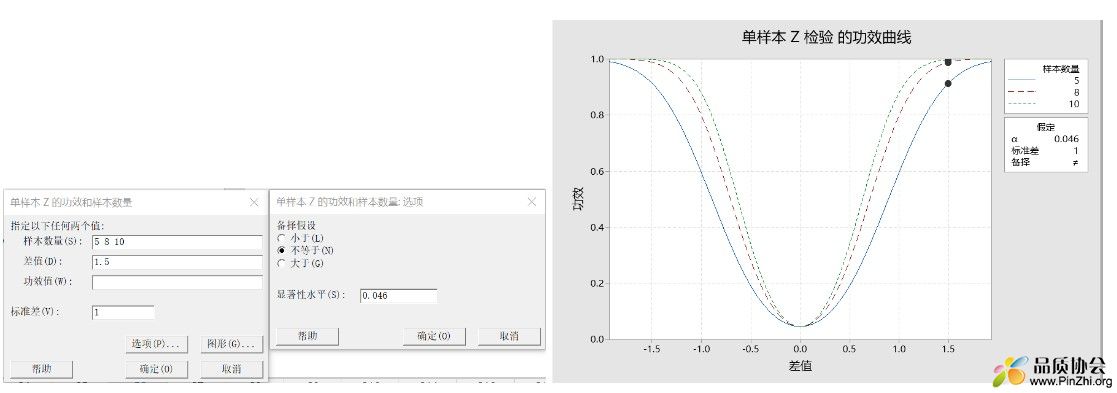
个人建议:在取样数量有限,但是又想降低漏判风险,尽早检出变异,可以考虑加严管控线,此时关注在判异规则一:一个点超过管控线。
如此时出现超过管控线的情况,有可能是严判,则需要增加样本量(降低检验标准误差)实施单样本t检验,以判定是否存在显著变异。(假设检验内同参考本人的另一篇帖子《检验合集》)
当然,检验过程小变异还有其他方法,如CUSUM控制图等,但此类控制图存在需要主观调参和应用条件限制。因此以上方法也可以作为特殊情况下方案考量。
章节三
大家好,本节我们继续上一节未完成的部分:
抽样的频率多少为宜?
抽样频率的关键影响在于,当过程发生变异时,能够多早的识别报警。
如果只单纯考虑此点,那么抽样频率越高,则发现过程变异越早,如果能实施过程全数检验,那当然时最理想状态。
在实际运用中,成本是必须要考量的,抽样频率要根据过程的稳定性进行设置,同时考量无法避免的到4M1E的结构性变化,比如班次,批次,材料的变更,设备的维护保养和关机重启等等。
那么在统计分析上,有无量化考量的方法呢?
答案是有的,这就是平均链长(ARL: Average run length)。平均链长即控制图从测量开始,到异常报点之间的正常点数。
ARL = 1/p, p即异常超出控制线的概率。我们举一个简单的均值控制图的例子,假设受控过程均值=0,均值标准误差为1,控制线设置为±3σ。此时若过程均值已变异为=1,标准误差不变(如下左图),那么识别此程度变异的平均链长是多少呢?首先计算均值为=1,标准误差为1的分布,超过3的概率(另一侧超出-3的概率很小,就不计算了),由下右图可知,p ≈ 0.023。
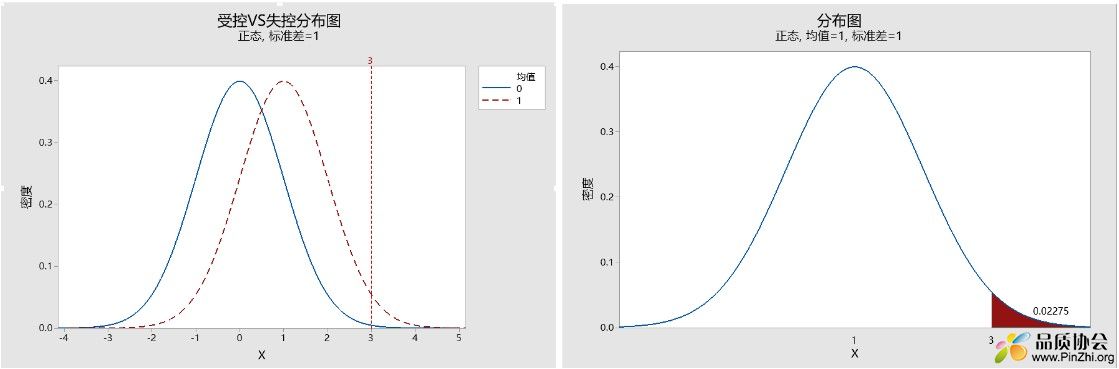
根据上面的P值可计算出平均链长,ARL = 1/p = 1/0.023 = 44(上取整) ,也就是说,当均值偏离控制中线1个西格玛,平均需要44组数据才会报出超控制线的情况。因此可见抽样频率越高,异常的识别越早。
ARL的缺陷?
ARL作为评估控制图识别异常能力的一个指数:ARL越小,则控制图识别给定变异程度(偏离中心线的大小)的能力越大。
但ARL存在如下两个主要缺陷:
1. 链长的定义符合几何概率分布。几何概率定义了在给定几率下,事件第一次发生时的实验次数。几何分布是一种严重右偏的分布,ARL作为均值,在严重偏倚的分布中缺乏代表性。
大家可以看下图p=0.023时的几何分布,此分布的均值μ=1/p =44 = ARL, 大家可以从图中看出此分布的均值对整体的代表性如何?
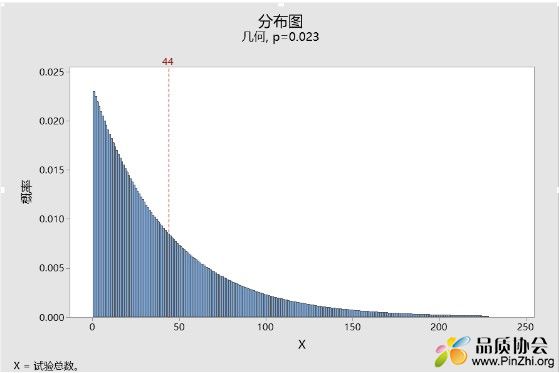
2. 链长的另一个缺陷是,几何分布的波动很大。几何分布的方差σ² = (1-p)/p²,以p=0.023为例,其几何分布的标准差可以此公式开根求得:σ = 42.975。也就是,当p =0.023时,链长±1σ波动范围为44 ± 42.975,这个波动是相当大的,同时也展示ARL作为点估计代表性很差。
以上两点作为ARL的诟病,供各位读者参考了解。
ATS与抽样频率的成本考量。
有一种将ARL与抽样间隔时间一起考量的指标,称为ATS(Average time to signal),可以翻译为平均报警时间。
ATS的计算公式非常简单: ATS = ARL * t ,其中t为时间单位,可以是天、小时、分钟等。
我们可以利用ATS计算异常发生时,按照给定的抽样频率,潜在的损失成本:
注意:以下为个人观点,仅供参考:
假设抽样频率为4小时一次,按照p=0.023计算,ATS = ARL*t = 44 * 4h = 176h, 也就是当异常发生到控制图报警的平均时间为176小时,我们带入过程开动率,加工Cycle time(注意时间单位要与ATS一致),异常产品的单位处理成本(可根据此过程此控制项过往挑选,返修,报废等异常处置总成本除以过往异常批产品数估算得出),可以按照下式估算:
(ATS * 过程开动率)/Cycle time * 异常品单位处理成本 = 一次异常处置成本
你也可以在上式基础上乘以此过程此控制项的年度异常发生次数,以估算在此抽样频率上年度的异常处置成本,并与此过程年度抽样成本做比较,以判断是否有必要增加抽样频率。
由于ATS主要以抽样时间间隔为考量,而我们实际实施SPC的过程中,有可能是按照批次进行抽样。因此我们参照ATS的公式,发明平均报警批次这一概念,我们给其命名为ABS(Average batches to signal)ABS = ARL * n batches 。其中n 为抽样间隔批次,如每批抽样两次,则n =0.5。
按照上例中的数据,假设我们每批抽样一次,则n =1 , ABS = ARL * n batch = 44 *1 batch = 44批。意味着异常发生后,平均需要44批抽样才会发现超出控制线的情况。
其成本的估算可以参照下式:
ABS * 批次平均员数 * 异常品单位处理成本 = 一次异常处置成本
以上是关于控制图抽样频率的一些知识点和个人见解,供大家参考。
章节四
大家好,本节我们使用半导体晶圆生产中,后烘后光刻胶宽度测量数据,进行研究型X-R图的实际操作。
数据大家可以参考本贴附件中的Hard_bake 文件。
本数据包含25组,每组5个测量数据。以下使用MINITAB 19进行实操。
第一步:数据整理。
首先我们看到数据的格式,其中Sample一列,代表抽样子组,列标题中的1-5,代表每组中的样本号。这种列联表的格式非常不适用与Minitab数据分析,因此我们使用数据-> 堆叠->行(如下图中),对数据格式进行处理,将行数据转为列。调整后数据全部在数据列,组号和样本号分别单独入列。
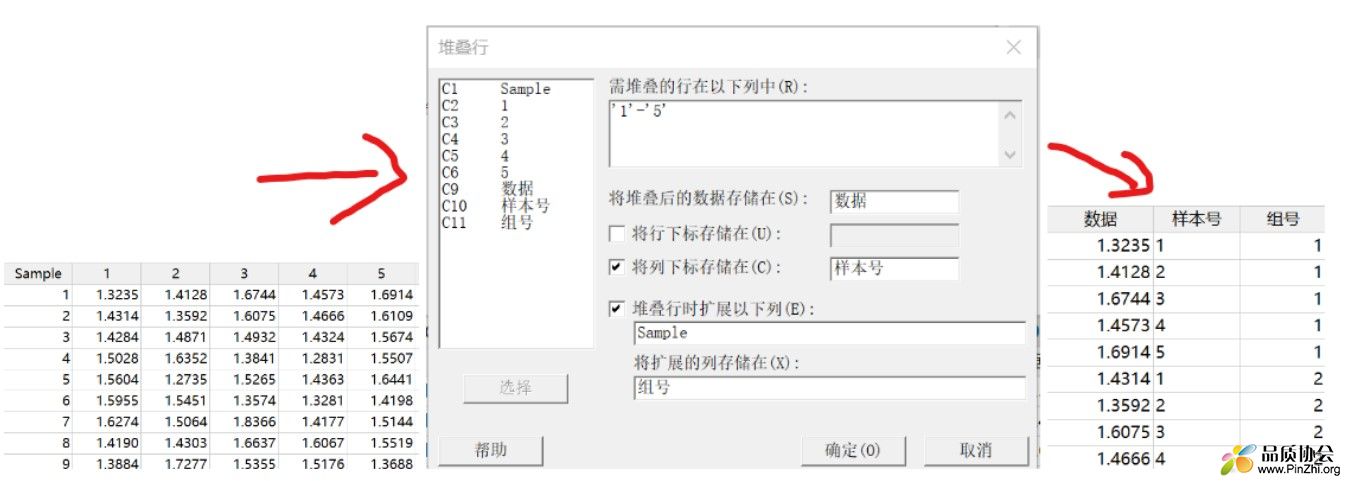
下面我们要确认下数据中是否存在异常值,如空值或因输入错误造成的异常数据。分别使用数据->条件格式->突出显示单元格->缺失观测值 以及 数据->条件格式->统计->异常值(本例选择箱线图)。可以发现第16组的5号样本为离群值,数据超出了1.5倍IQR,因此标红。但此数据与其他数据差异并不大,本例不做处理。(如差异较大时,可进行复测,以判断是否存在测试操作问题或数据录入问题)

第二步:数据检验。
首先参考以X-R图制图数据的基本要求:

其中1,2,3,4在数据取样及记录时,就必须满足相应要求。本例默认已满足要求。
要求5,本例子组数据为5,适用X-R图。要求6,本组数据共125个,满足要求。
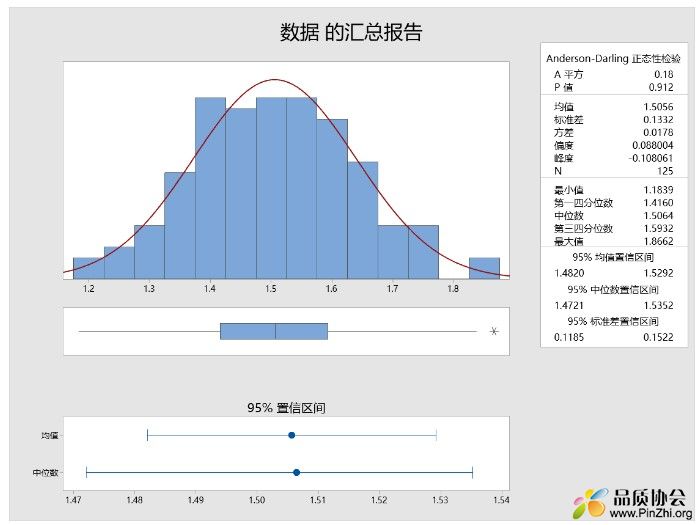
要求7,数据应尽量满足正态分布,特别要注意数据分布是否存在显著双峰、断壁等结构,以判断数据是否来不同总体混合或有偏抽样(如被挑选)。此处无需正态性检验,建议使用直方图观测: 本例采用统计->基本统计->图形化汇总。从下图直方图中可以看出,数据符合正态分布,没有结构性异常。均值、中位数、偏度等多个指标也显示数据无偏。
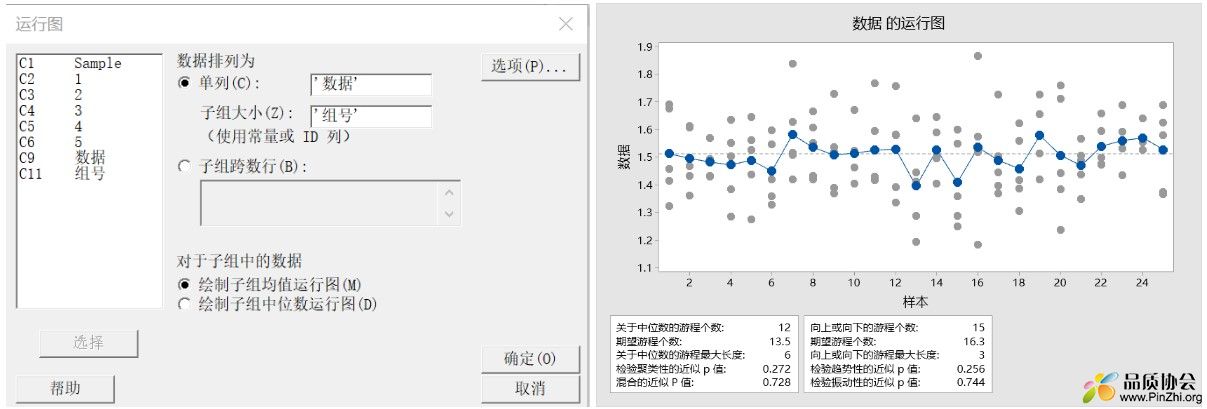
要求8,需确认数据是否存在自相关现象。即持续上升或下降等规律。如存在此种规律,说明过程收系统原因影响而规律性波动,此时应识别并改进此系统原因。可使用游程检验或运行图,判断数据分布是否随机。本例数据子组样本数>5, 选择使用运行图。统计->质量工具->运行图。 本例数据符合正态分布,选择子组均值运行图。
下右图游程检验,可见各检验p值均大于0.05,可见无统计显著的规律性。其中趋势性检验p值为0.256,无显著自相关。
以上综合,数据符合X-R图制作数据条件。
第三步:控制图制作。
选择控制图->子组变量控制图->XbarR;
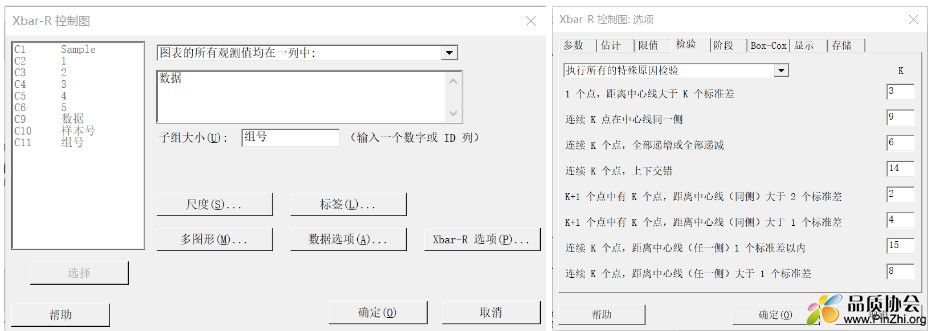
这里面主要讲Xbar-R选项,其他几个选项为图形输出和数据输入相关,不做展开。
- 参数:如制作量产控制图,可根据过往受控批次的数据计算均值和标准差,这样更为合理。
- 估计: 此处选择标准差的估计方法,选择Rbar即可。
- 限值: 此处可设定控制线为多少倍标准差?其影响可参照本贴第二章说明。如控制线已固化,也可直接输入控制线。下面点选使用子组实际大小,当各子组员数不一时,可加权计算。
- 检验 : 请选择执行所有特殊原因检验,其标准如上图。其中K是可调整的,其α计算请参考六西格玛红宝书相关内同。
- 阶段: 可增加一列已区分阶段,用以对比过程变化前后SPC趋势。
- BOX-COX:数据不符合正态时,可进行正态性转换,注意此时中心线及控制线均为转换后数值。
- 显示:·不用做特别调整。
- 存储:存储您想要记录的统计量。
制作后控制图如下:

第四步:判异。
首先确认R控制图,控制图无异常。其中第16组数据R较大,与之前数据整理时的离群值相呼应。但仍在控制线以内。
再看Xbar控制图,控制图正常。
此例为研究型控制图,根据控制图结果,可以判断过程稳定受控,下一步可展开能力研究。
以上为X-R图制作的详细说明,其他单变量控制图就不再说明。
本章就写道这里,下节开始,我们讲一点特殊单变量控制图的运用。
章节五
大家好,从本章开始,我们一起来探讨一下单变量特殊控制图的运用。
本节简单介绍下CUSUM控制图,即累计和控制图。
我们在第二章有介绍,当过程变异较小,如均值变异在1σ,则需要ARL=44,平均44个数据点才能识别过程均值的变化。因此当需要识别过程的小变化(指变化<1.5σ)时,可以考虑使用累计和控制图进行监控。
累积和的概念很简单。此处的累积和指的是过程数据据与给定总体均值差的累计和。假设当过程受控时,总体均值无变化,数据应该围绕均值中心上下波动,那么数据与总体均值的差异平均值μ差异 = 0, 那么n个数据的差异的累计和应该 = n * μ差异 = 0。
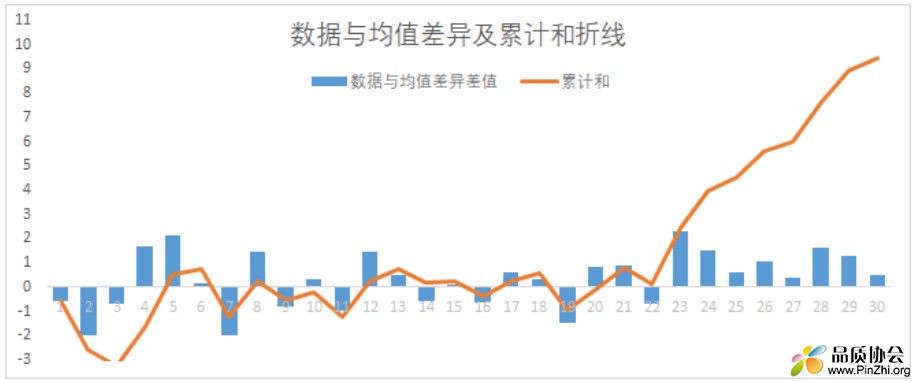
如果过程发生变化,那么过程数据与均值的差值均值则不等于0,而这种差值的累计和 n * μ差异 就会随着样本量的增大而越发偏离0。下图为一个简单的例子,其中前20个数据符合均值 = 10,标准偏差 =1 的正态分布,后10个数据符合均值=11,标准偏差=1。以下图例展示中柱状图展示了各抽样数据与均值μ=10的差值,折线图展示了差值的累计和。可以看到从第21个数据起,随着均值变为μ=11,差值在累计增加。(图例数据可查看附件中CUSUM EXCEL附件)。
以上是简单说明了累计和的概念。那么累计和控制图较上图稍复杂一点,CUSUM控制图需要统计两个统计量,C+和C-,其中C+可以理解为为样本数值-(均值+参考值)>0的数值的累计和,C-可以理解为样本数据 - (均值-参考值) <0的数值累计和。其计算公式如下(Minitab计算方法):
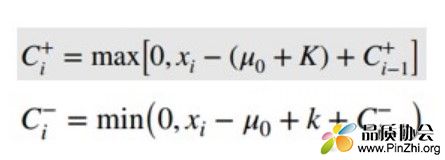
其中k被称为参考值(见六西格玛红宝书),k通常设定为需要检验差异的1/2。以上面数据为例,过程原均值=10,变异后均值=11,那么差异为1。此时如需检验差异δ≥1,则设定k=1/2*δ。有时差异会使用标准偏差倍数的方式,以上题为例,δ=1=σ,则k可以表达为:k = 1/2 *δ*σ = 1/2 *|μ1-μ0|/σ * σ = 1/2 *|11-10| = 0.5。
除了计算控制用统计量C+和C-,还需要计算控制线h。h通常设定为4倍或5倍标准偏差。有了原数据和以上统计量的计算方法,那么就可以很容易使用EXCEL制作CUSUM控制图,如下就是使用EXCEL制作的简易CUSUM控制图:(可参考附件CUSUM)
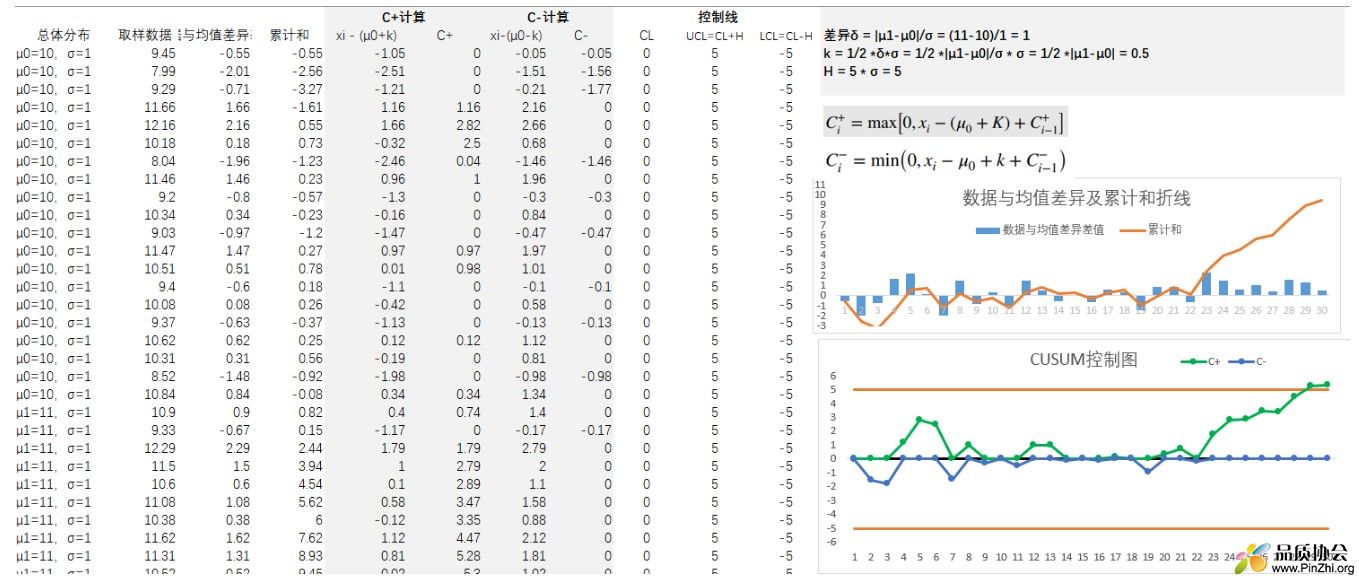
大家可以根据右下角的图片,识别到C+统计量从23位起持续升高,到29位时已超过上控制线(h = 5 * σ = 5), 说明CUSUM控制图可以快速识别1个σ大小的变异。
下面与常用控制图做对比,本例数据是子组=1,因此使用IMR控制图与CUSUM控制图进行对比:
下面使用MINITAB进行操作对比,其中标准偏差的估计均使用步长=2的移动极差平均值法。其中CUSUM,目标值设定=10,方法设定为表格式,h=5,k=0.5。
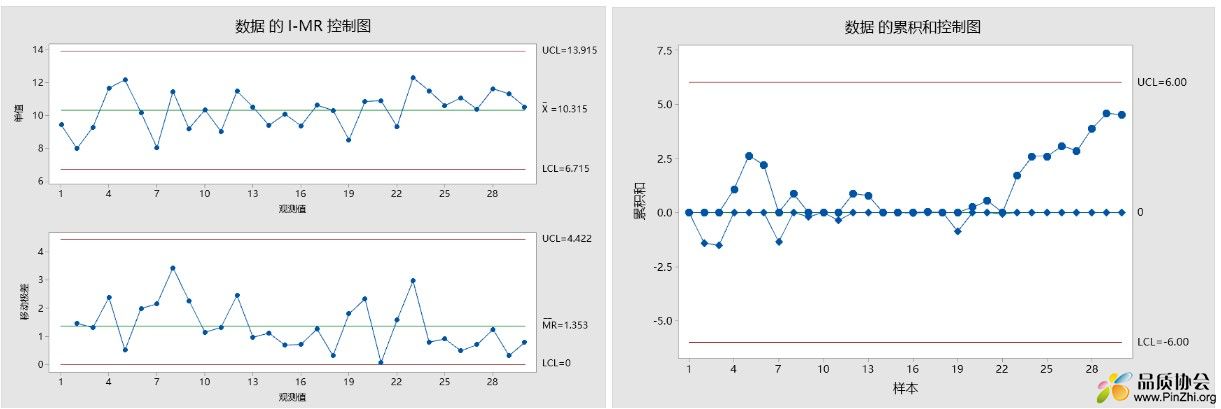
其中,左上图为IMR控制图,实施了所有判异但未发现异常。右上侧为CUSUM控制图,可见从23点起数值持续上升,但未超过控制线。这是为什么呢,这是因为两者均使用移动极差平均值来估计标准偏差,按照MINITAB的推荐,子组=1的单值数据应达到100个数据以上,估计效果才较好。本例数据标准偏差估计值=1.19,因此控制线h=5σ≈5S=5*1.19=6, 控制线由于抽样原因放大,未判定异常。在实际使用情况下,通常实在常用控制图稳定的情况下,才会考虑使用CUSUM控制图监控过程的小变异,此时可根据过往数据计算σ,直接在选项->参数中输入总体标准偏差的估计值。
那么,CUSUM在识别小变异的过程中较常规控制图的优势有多大。我们在第三章中介绍了ARL的概念,其中有说明,当差异=1σ是,休哈特控制图的ARL≈44,大家可参考下图(摘自 Introduction to Statistical quality control, 8th edition, Montgomery)
可见当过程均值变异=1σ,此时设定h=4,则ARL = 8.38, 即平均需要8-9个样本数据即可识别过程变异。
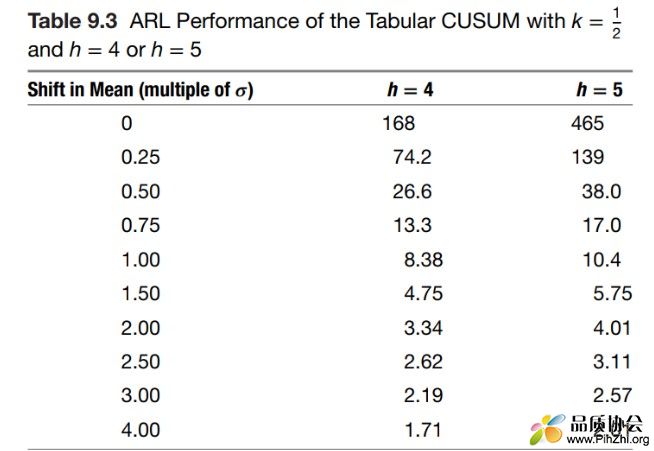
其中h的设定与检验的α风险相关,其中h=4.77时,其α风险与休哈特控制图的3σ控制线相当,即α<0.3%。使用者可据此设定h值,h值越小则检验能力越强,β越小,ARL越小,但是α风险上升。CUSUM控制图的ARL计算公式比较复杂,本贴就不再展开,有兴趣的朋友可以查阅相关资料。
补充说明:
1. CUSUM控制图虽然对于过程小变异识别率高,但是在识别过程较大变异或规律性变动(比如均值上下规律性波动)上面,不如常规控制图。
2. CUSUM更适用于单值的控制图,当然也可使用于子组>1的情况。关于利弊,大家可以参考 Introduction to Statistical quality control, 8th edition, Montgomery,书中有详细说明。
以上是表格法CUSUM控制图的介绍。除了此种方法,还有V-MASK方法,MINITAB也支持此种方法的CUSUM控制图制作。本贴不对此种方法展开,有兴趣的朋友也可参考相关资料自行研究。
关于其他过程小变异检验的单变量特殊控制图
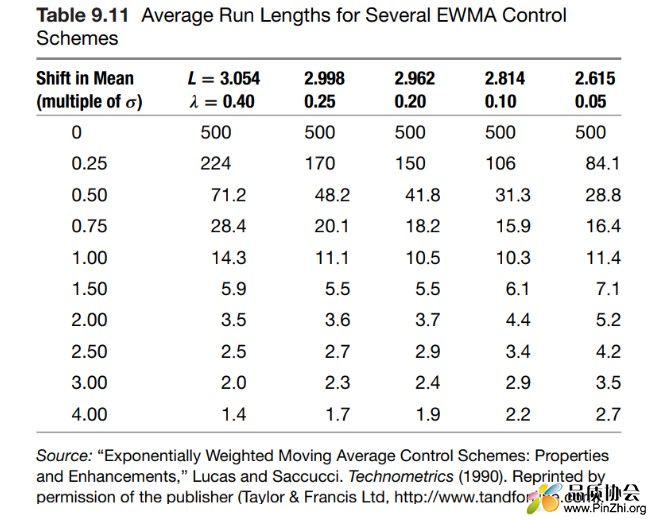
关于过程小变异的控制图,六西格玛书籍上除了CUSUM控制图外,还提及了EWMA(指数加权移动平均)控制图。EWMA在六西格玛蓝宝书上有详细介绍,此处就不再追溯,仅简单说明一下权重参数λ和控制线L的设定。其中λ为当前数值权重,L为控制线 = σ的倍数。可以根据此两个参数调配控制图的ARL及α风险水平。以上题为例,参考如下列表:
当λ=0.1,L=2.8时,起ARL与CUSUM控制图k=0.5,h=5 相当,可供大家参考。
以上是本章节的内容,我们下章再见。
|
|
 [复制链接]
[复制链接]



 发表于 2022-5-6 13:42:10
发表于 2022-5-6 13:42:10



 发表于 2022-5-6 14:05:57
发表于 2022-5-6 14:05:57

 楼主
楼主
 发表于 2022-5-7 07:04:36
发表于 2022-5-7 07:04:36

